Content-based Image Retrieved System II
For the extraction of color and texture part, see Content-based Image Retrieved System I
II Realization
- HOG-based shape feature extraction
HOG (Histogram of Oriented Gradient) means the histogram of orientation gradient, which is a description of the histogram of gradient orientation by counting the number of orientations of a certain pixel or pixel area edge in the image local features. By normalizing the image to form a consistent spatial density matrix and other methods, Hog’s calculations have been able to achieve a certain degree of accuracy, so this technology is widely used in image recognition and processing, SVM classifiers and computer vision.
The core idea of Hog is to detect the distribution of the local contour information of the object. The contour information here includes the surface color, illumination, edge, texture and other image features. He calculates the gradient histogram of the area and saves it in the feature database, so it can It is a good description of the prominent surface features of the object. However, there is a problem that Hog is not robust to the invariance of illumination due to being too sensitive to color and contour information. A little light change on the surface of the object will cause the hog calculation to extract The feature histogram changes.
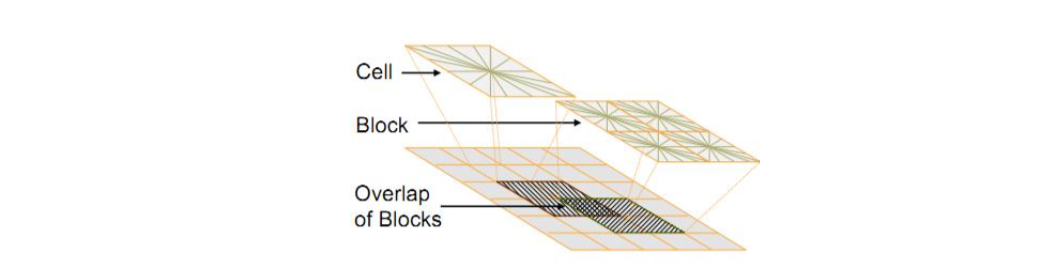
The relationship between Block and Cells is shown in the figure:
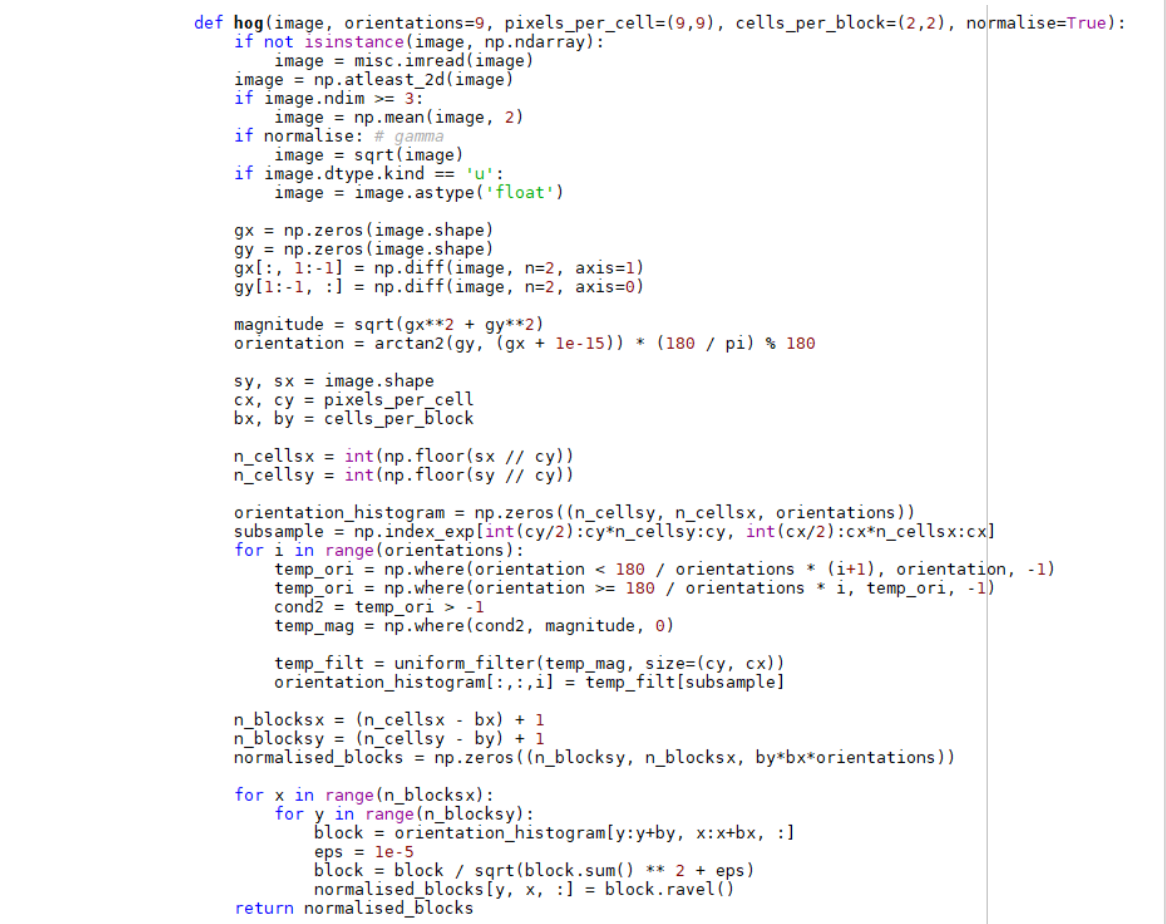
The HOG geometric feature extraction code is as follows: define the hog extraction function, define the parameter size of block, cell, etc., and then normalize the image, the integer is square, and the extra area is filled with 0. After calculating the direction gradient of each pixel, the gradient function is mapped downward, and finally the result is mapped to the Hog feature histogram.
- Image feature extraction based on local features
(1) SIFT local feature description
SIFT is a feature descriptor that describes the local features of an image. Its essence is to find key points in different scale spaces and calculate the scale invariance-based feature transformation of the key point direction. It has nothing to do with the image size and angle, and has a good Robustness. SIFT search is characterized by some very prominent points, such as corners, edges, bright spots in dark areas and darker points in bright areas. These points will not change due to lighting, environmental changes and noise. Therefore, the SIFT algorithm has a high success rate in searching for light, noise, and microscopic image changes. Based on these characteristics, the SIFT algorithm has a high degree of similarity, easy to identify objects, and a low rate of misrecognition.
(2) SIFT descriptor formation steps
The generation of the SIFT descriptor is very complicated. The first step is to construct an image in the Gaussian difference space: Before understanding the difference of Gaussian image (DoG, Difference of Gaussian), the meaning of the image pyramid must be clarified. The image pyramid is to pass the image through different pixels. The displayed image group includes up-sampling and down-sampling: up-sampling is to gradually increase the scale of the image through zero-filling and other methods, so the picture will gradually become unclear; down-sampling is to gradually reduce the scale of the image through compression.
After obtaining the image pyramid, the Gaussian function of pictures of different scales must be calculated. The calculation method is as follows:
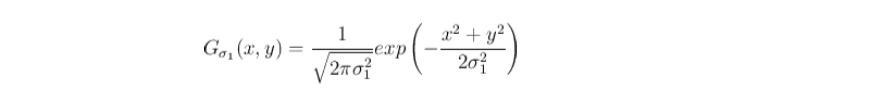
Then the two adjacent size images are Gaussian filtered to get g1(x,y), g2(x,y):
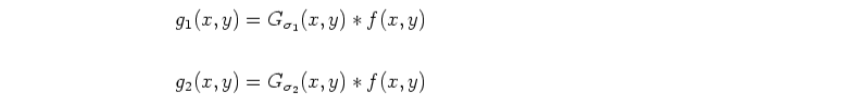
The two-type subtraction obtains the Gaussian difference image of two adjacent images at this size:
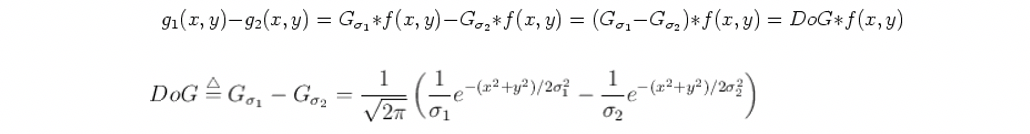
For the Gaussian pyramid, the default is 4 layers (octave), because each layer has 5 different scale images, and these 5 images can be subtracted to get 4 different differential Gaussian images. In my system, the selected sigma of the scale is 0.8. As shown in the figure, the coefficient k before sigma is a smoothing coefficient, which is used to construct image pyramids of different scales.
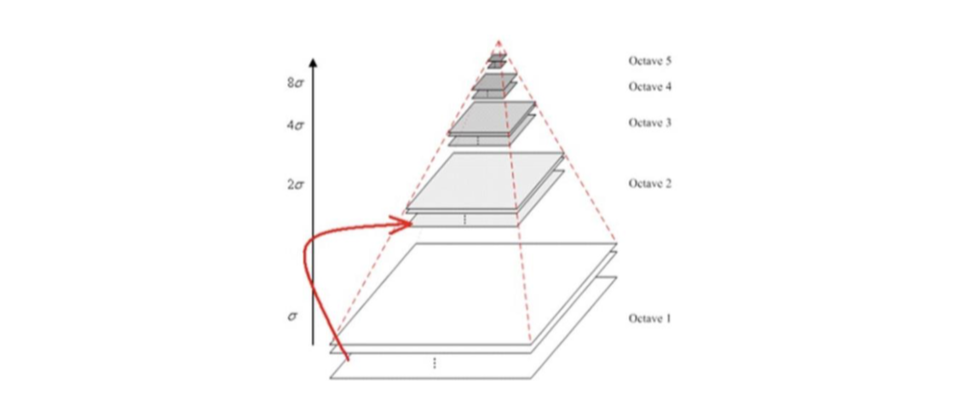
Next step 2, find the maximum and minimum points in the space: compare each pixel with the 26 pixels directly adjacent to it in space. If the pixel is an extreme, it is a feature point. The reason why there are 26 pixels adjacent to it, the pixels in space can be imagined as a Rubik’s Cube, and the most central block of the Rubik’s Cube is compared with the remaining 26 points surrounding it, and the result can be obtained. As shown:
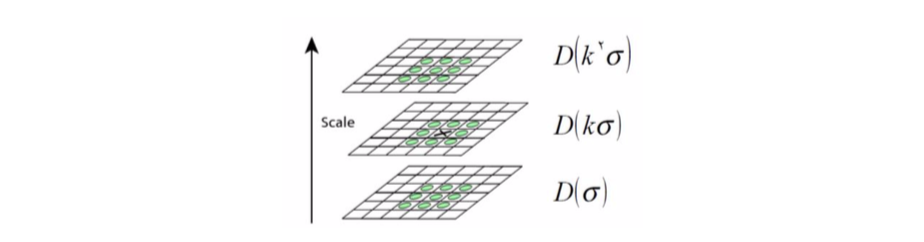
Step 3 is to select the main direction of the feature points. First, select an appropriate area for the feature points found in step 2, as shown in Figure 2-9. Perform gradient direction histogram statistics on this area, and the statistical results are as shown in the right figure. Set the direction with the largest proportion in the histogram as the main direction. The size of the selected area is related to the image scale. Generally speaking, the larger the scale, the larger the area.
Simple code:
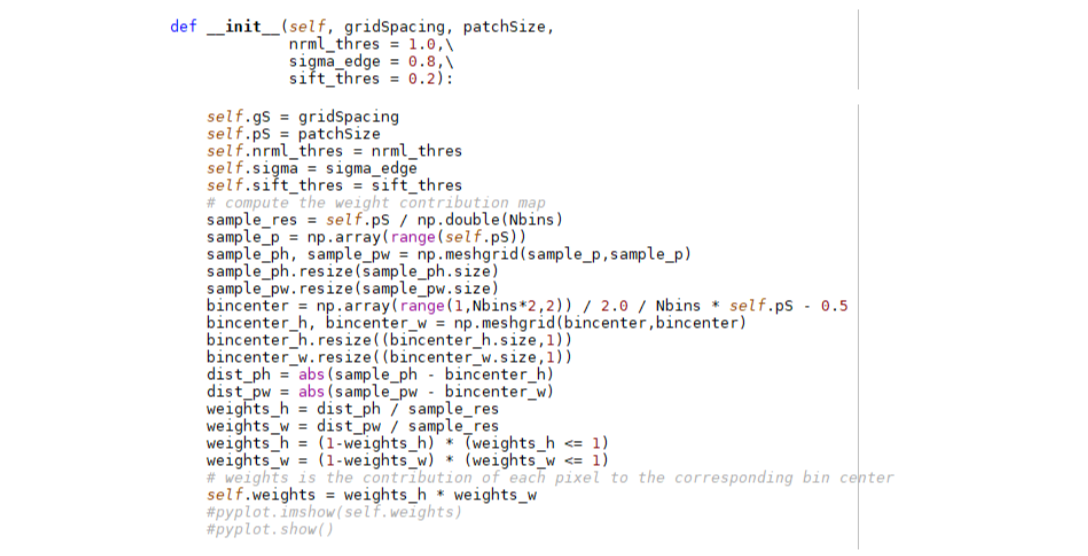
III References
[1] Wu Lijun, Wen Jicheng, Chen Zhicong, Chen Jinhuo, Lin Peijie, Cheng Shuying. Improved SIFT algorithm to achieve fast image matching. Journal of Fuzhou University: Natural Science Edition, 2017, 45(6): 801-809.
[2] Liang Shufen, Fu Yingying, Yang Fangchen. Smiling face recognition method based on Gabor fusion feature and deep autoencoder. Information Recording Materials, 2019(1): 83-84.
[3] Li Mingdong. Research on HOG feature multi-target tracking algorithm. Journal of Lanzhou Institute of Technology, 2018, 25(4): 58-61.
[4] Jian Zhao ; Hengzhu Liu ; Yiliu Feng ; Shandong Yuan ; Wanzeng Cai. BE-SIFT: A
More Brief and Efficient SIFT Image Matching Algorithm for Computer Vision.
[5] Xiao Manyu, Lu Jianghu, Xie Gongnan. Image retrieval optimization based on SIFT feature vector. Applied Mathematics and Mechanics, 2013,34(11):1209-1215.
[6] Cui Weiqing, Dang Changchun, Zhang Wang, Wang Hongzhou, Luo Yongya. A HOG feature template matching algorithm. Machinery Management Development, 2018, 33(11): 252-253.
[7] Zhou Gang, Sun Mengxue, Gao Yan. Design of a face feature image retrieval system based on OpenCV. Electronic World, 2018(23):137-138.
[8] Bian Jiayin, Shan Luping, Huang Jiasheng, Wang Quanming, Luo Yuantai, Chen Qiang. Excavator detection algorithm based on multi-feature fusion. East China Science and Technology: Academic Edition, 2014(7): 24-27.
[9] Mehdi Ghayoumi ; Miguel Gomez ; Kate E. Baumstein ; Narindra Persaud ; Andrew J. Perlowin. Local Sensitive Hashing (LSH) and Convolutional Neural Networks (CNNs) for Object Recognition.
[10] Yin Ying. Image retrieval based on color-space two-dimensional histograms. Fujian Computer, 2009(10): 92-93.
[11] Yang Xingbin, Lu Jingguo, Zhang Danlu, Cheng Zhe. A tilted aerial image matching method combining Dense SIFT and improved least squares matching. Bulletin of Surveying and Mapping, 2018(10): 32-36.
[12] Tang Haoyang, Sun Ziwei, Wang Jing, Qian Meng. Clothing image recognition based on VGG-19 hybrid migration learning model. Journal of Xi’an University of Posts and Telecommunications, 2018, 23(6): 87-93.
[13] Yang Xiaopeng, He Xiaohai, Wang Zhengyong, Wu Xiaoqiang. An interactive image segmentation algorithm based on GrabCut. Science Technology and Engineering, 2018, 18(26): 207-212.




